Trip report - Meeting C++ 2017
Posted on Thu 16 November 2017 in C++
Finally, after years of watching youtube videos on that topic, I made it to my first C++ international conference! Thanks to my current employer King, I went last week to Meeting C++ in Berlin, which is, as far as I know, the biggest C++ event in Europe. I really enjoyed my time there with few hundred other fellow C++ enthusiasts. In this post, I will try to relate how I experienced the event and dress a list of the must-watch talks.
About meeting C++:
The concept:
![]()
Held in the magnificient Andels Hotel in Berlin, Meeting C++ offers the possibility to attend keynotes, talks and lightning talks (respectively lasting 2 hours, 50min and 5min) about our favourite language C++ for 3 days (one extra day added for the 6th edition of the event). C++ being multi-paradigm and a general-purpose programming language, the variety of the topics being discussed is pretty wide. It ranges from subject on "(Template) Meta-programming" to a deep dive on "How a C++ debugger work", from begginner friendly talks to hairy discussions on the yet-to-be-standardised white paper on std::expected<T, E>.
As some talks happen simulteanously in different rooms, you cannot physically attend all the talks. Instead, you would usually prepare your own schedule by trying to guess the content of the talks from their summary. It is always a dilemna to choose between a topic that you like with the risk to have nothing new to learn, and a brand-new topic for you, where sleepness may kick-in midway to the presentation. If you are curious and daring, the lightning talks on the last day permit you to randomly discover antyhing about C++ in succint presentations. In any case, you can always catch-up the missed talks by checking the Youtube channel.
Generally, I was not disapointed by the quality of the slides and the speakers. I picked up quite a few new concepts, prepared myself for the future of C++ (C++20) and refreshed myself on some fields I did not touch for a while.
More than just talks:
Where Meeting C++ really shines is in its capacity to gather roughly 600 passionated developers from various backgrounds (university, gaming industry, finance, Sillicon Valley's giants...) in one building and share. Just share anything about C++, about reverse-engineering, about your job, about your country, about the german food in your plate! The C++ community represented at this event is very active, open-minded and willing to help. The catering between the sessions and the dinner parties permit you to meet anyone easily. The even team also oganises some really fun events
In a room full of "world-class developers", it is easy to be intimidated, but you should not hesitate to reach them. They will not nitpick your words nor snob you. For some people, it is a dream to meet an Hollywood Star in the street, for me it was really delightful to have casual conversations with these "legendary" coders from the web.
The chief's suggestions of the day:
Here is a menu of most of the talks I attended. The legend is pretty simple:
- 💀 : The difficulty of the talk (💀: Begginer friendly, 💀💀: Intermediate, 💀💀💀: High exposure to C++'s dark corners)
- ★ : My interest for the talk (★: Good talk, ★★: Tasty talk, ★★★: Legendary talk)
I will not spoil all the talks, but simply try to give an overview of what you can expect within them. Note that all the talks are generally of high quality and my appreciation very subjective. I have seen people with very different "favorite talk".
[Keynote] Better Code: Human interface - By Sean Parent - 💀 ★★
- Slides: link
- Video: coming-soon
Sean Parent is a Principal Scientist at Adobe Systems and has been working on the famous software Photoshop for more than 15 years. Sean Parent is a regular and prominent speaker at C++ conferences, one of his recently most famous talk being Better Code: Runtime Polyphormism from the same series of talks (Better Code) as the one he gave during Meeting C++.
Thorough his keynote, Sean was conveing the message that in order to have ergonomic human interfaces, you must design your code to reflects its usage through UI. By following such a principle, one can easily come-up with good namings, semantics and grouping of your UI components.
For instance, Sean was explaining that most of the menu actions in Photoshop somehow mapped some object, their methods, properties and most importantly their relations:
- The menu action Create New Layer will somehow call the constructor of a class called something like Layer.
- Likewise the action Delete A Layer would call its destructor.
- A selection in Photoshop will most likely translate in a container of objects.
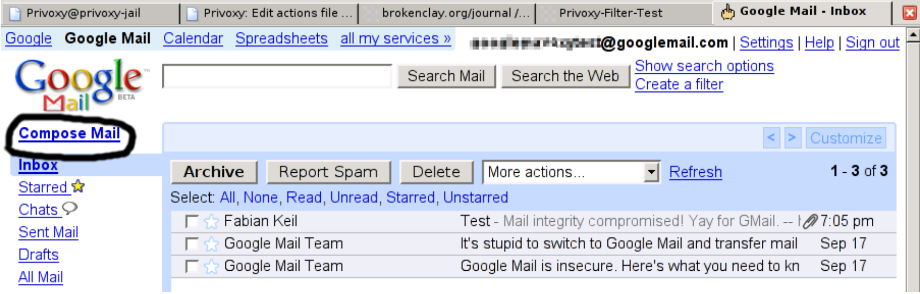
As a counter-example he explained that the old version of Gmail used to have a confusing flow when it comes to the most trivial usage of a mail service: creating a mail. A link, which implies navigation, was used instead of button for the "compose message" action.
Sean put a strong emphasis that relationships are the most difficult part of an architecture to represent. He came up with few examples on how std::stable_partition can be used to solve in an elegant way the gathering and display of items
Overall a very nice talk, but on a very abstract topic, since not much has been explored on that subject yet! This is worth paying attention in game-programming where a good UI is a key-part of the success of a game.
[Talk] Threads and Locks must Go - Rainer Grimm - 💀💀 ★
- Slides: coming-soon
- Video: link
In this talk Rainer Grimm, a German author of multiple C++ books, brought under the spotlight the concurrency features introduced by the new C++ standard C++17 and the coming one C++20. Here is a short summary of my favourite features:
For C++17 (and concurrency TS):
- The new parallel algorithms in <algorithm> and the associated execution policies seq, par and par_unseq.
std::vector<int> v = {...}; // A bit vector...
std::sort(std::execution::par{}, v.begin(), v.end());
// Due to "par", this **might** execute the sort in parallel using a thread pool of some sort.
- The new std::future interface which permits to add continuations to the shared state using the then member function.
std::future<int> foo();
auto f = foo();
f.then([](std::future<int>& f) {
// Will be called when f is done.
std::cout << f.get(); // Will therefore not block.
});
Hopefully for C++20:
- The stackless coroutines as implemented by MSVC and clang. This introduce two keywords co_await and co_yield. Considering the previous example using std::future, it could be rewritten in the following way:
std::future<int> foo();
int x = co_await foo(); // The continuation is "generated" by the compiler using the keyword co_await.
std::cout << x; // Everything after co_await is implicitely part of the continuation.
- A new synchronized keyword applying the transactional memory concept on a group of statements.
int x; y; // Global vars
void foo() { // Foo can be called by multiple thread simuteanously.
// Reads-writes on x and y are now thread-safe and synchronized.
synchronized {
++x;
++y;
}
}
As explained by Rainer Grimm, we will have the possibility to easily bring concurrency to our C++ codebases without ressorting to the low-level, and tricky to get right, features like thread and locks. While I appreciated the talk, it lacked a bit of novelty as I was already aware of most of the features.
[Talk] Strong types for strong interfaces - Johnathan Boccora - 💀 ★★★
A must watch! Even when facing some technical issues, Johnathan is very good speaker and I was quickly captivated by the topic of strong types. Jonathan is also a talented writer with his famous blog fluentcpp (I would really suggest to have a look at it once in a while).
As C++ developers, we heavily rely on the language's type system to express our intentions to other developers, to optimise our code and avoid shooting ourselves into our feet. Yet, we always reuse some types to express very different properties of our system. For instance to describe a person, you would use an int for her/his age and his/her weight. Did it ever come to you that the unit year (for age) should be a very different type than kg (for weight)? The concept of strong type would solve this problem by introducing new int-compatible types:
// We need to have these empty tag types to create entirely new types and not just weakly-typed aliases.
using kg = strong_type<int, struct KgTag>;
using years = strong_type<int, struct YearsTag>;
void unsafe_create_person(int age, int weight);
void create_person(years age, kg weight); // Explicit interface.
int age = 42;
int weight = 1337;
unsafe_create_person(weight, age); // Oops I inversed the arguments but no compiler error.
create_person(years(age), kg(weight))); // Much less error-prone.
As a bonus, strong types can actually affect positively the performances of your codebase as the compiler can agressively optimise without violating strict-aliasing rules, since the types are now strictly unrelated.
This concept is not new and is already used in std::chrono or Boost.Unit, but it was really refreshing to have an explanation with simple words and good examples! I am now very keen to use this in my personal projects and at work too.
[Talk] How C++ Debuggers Work - Simon Brand (4/5) - 💀💀 ★★
Simon Brand, also known as TartanLlama (a really fancy fictious name for a Scott), presented us how a mixture of calls to ptrace, injection of the int3 opcode, parsing of the DWARF format and perseverance is the base to create a debugger on a x86(_64) architecture with a Unix platform (or Linux platform only if you OS specific calls like process_vm_readv, process_vm_writev).
Unlike some of the other talks, it would be hard to give succinct code examples, but I trully appreciated his presentation! When it comes to low-level APIs for debbuging and reverse-engineering, I have a better understanding of the Windows platform. I think that Simon did an excellent job to help me transfer my knowledge to the Unix world.
If one day I have to tackle the creation of a debugger on Unix, I would certainely come back to this talk or follow his series of blog posts on the same subject. I also think that as programmer, it is always beneficial to have some knowledge on the underlying mechanims of the tools you use (gdb, or lldb in that case). I would, therefore suggest to watch that talk to any C++ enthusiast willing to progress in their art of programming.
[Talk] The Three Little Dots and the Big Bad Lambdas - Joel Falcou - 💀💀💀 ★★★
- Slides: coming-soon
- Video: link
I am always excited by watching a talk from Joel Falcou: he is a venerable (template) metra-programmer wizzard with a very didactic approach to explain things (and also we share the same nationality \O/). Once again, I was not disapointed by his session.
With a lot of humour, Joel introduced a new facet to meta-programming in C++. We used to have template meta-programming to manipulate types at compile-time (and with difficulties values), then came constexpr to ease value computation, and recently a Louis Dionne came-up with a powerful combo of these two cadrants with Boost.Hana. Joel statement was that lambdas expressions combined with auto and parameter packs are powerful enough to replace some cases where we would have resort to use template meta-programming or the uglier infamous macros! Joel came to that conclusion after being inspired by the language MetaOCaml.
Let's say that you want to fill a vector with push-back instruction generated at compile-time:
#include <tuple>
#include <iostream>
#include <array>
#include <utility>
#include <vector>
template <class F, std::size_t... I>
void apply_imp(F&& f, std::index_sequence<I...>) {
(f(I), ...); // C++17 fold expression.
}
template <int N, class F>
void apply(F&& f) {
apply_imp(f, std::make_index_sequence<N>{});
}
std::vector<int> bob;
auto bind = [](auto& v, auto f) { return [&v, f](auto x){ f(v, x); }; };
auto push_back = bind(bob, [](auto& v, int x) { v.push_back(x * 3); });
apply<3>(push_back);
// Will generate at compile time:
// bob.push_back(0);
// bob.push_back(3);
// bob.push_back(6);
This example is fairly trivial and there would be a high chance that you would reach the same assembly output using a simple for loop. But it is very interesting to notice that lambdas are reusable type-safe units of code that you transport, combine and "instantiate" at any time. Performance-wise, lambdas are pretty incredible according to Joel's measurement on his linear-algebra project. C++17 constexpr lambdas could also help on that topic. One drawback might be the debugging complexity when navigating in nested lambdas. I still need to wrap my head around this new concept and I am eager to rewatch Joel's talk to explore it more!
[Keynote] Its complicated! - Kate Gregory - 💀 ★★★
- Slides: coming-soon
- Video: link
While excellent, Kate's keynote would be very hard to summarise correctly within few paragraphs. It makes you reflect on the difficulties to introduce C++ to newcomers. You would hope that there is a subset of the language that could be easily assimilate by anyone, Kate argues that the reality is sadly more complicated than that. Just have a look at how long are the C++ core guidelines on passing parameters to function calls. One day or another, a begginer must learn on how to pass parameters with good semantics and in an optimised fashio. Well, good luck to her/him! On the other hand, it does not mean that the language could have been designed in a simpler way. What we should strive for instead might be better naming of these concepts: the acronym RAII (Resource Acquisition Is Initialization) is obviously not as straightforward as COW (Copy-on-write). Whether you are a "newbie" or the best "lead over-engineer" of your company, this talk is really worth a look!
[Talk] There Is A New Future - Felix Petriconi - 💀💀 ★★
- Slides: coming-soon
- Video: link
Felix Petriconi and Sean Parent have been working on a the stlab library for quite some time. stlab takes the best of the various future implementations std::future (C++11), std::future (C++14) or boost::future, and adds a bit of it owns features on top of it. For instance, stlabs supports passing explicit executors to control where async will execute the tasks, and where the continuation associated with then will be executed too. Executors are akin to event-loops (or message-pumps in the .Net world) that will process the tasks.
// This task will be executed on ``an_executor``
auto f = stlab::async(an_executor, [] { return 42; });
// The continuation on another executor.
f.then(another_executor, [](int x) { std::cout << x; });
While executors are present in Boost.Thread, stlabs's channels are unique to this future library. Channels are one of the Go language's favorite toy. It is a neat way to create communication between a sender and a receiver on different executors:
auto [sender, receiver] = channel<int>(receive_executor); // Create the link.
receiver | [](int x) { std::cout << x; }; // Define what should happen at the reception.
// Establish the connections.
receiver.set_ready();
sender(42); // Sent 42 through the channel.
// Receiver will print 42 when executing the task.
I really like some of the features in stlabs, hopefully this could be incorporated into the C++ standard (the executors are down in the pipe of the standardisation process).
[Talk] Introduction to proposed std::expected - Niall Douglas - 💀💀💀 ★
- Slides: coming-soon
- Video: link
Are you the kind of person that would rather have errors on the return values rather than using exceptions. Niall has a solution for you: std::expected<T, E>. You can see std::expected<T, E> either as a std::optional<T> with a empty state containing an error for being empty, or as a std::variant<T, E> where you agree that the first alternative is the return value and the second alternative is the potential error. Example:
std::expected<int, std::string> foo(int x) {
if (x < 0) return std::make_unexpected("x < 0");
return 42;
}
auto result = foo(-1);
if (!result) std::cout << result.error().value(); // Prints " x < 0".
std::expected starts to be cumbersome to use when combining or propogating returned results. To palliate this problem, std::expected exposes a Monad interface, with the bind member function coming directly to your mind. If you are a Haskell user, std::expected should remind you of the Maybe Monad. Using bind is still verbose and hopefully we obtain a dedicated keyword try to ease our pain.
[Talk] The most valuable values - Juan Pedro Bolívar Puente - 💀💀 ★★
- Slides: coming-soon
- Video: coming-soon
During his presentation, Juan actively promoted value semantic over reference semantic and did so with some analogies from our physical world (from our dear philosopher Platos) and code examples. The talk quickly moved onto immutability and functionnal programming applied to user interfaces. There is a trend in the web sphere to follow a software architectural pattern called flux with a main implementation the redux framework. Arguably, flux is a glorified good old MVC (Model View Controller) architecture with a strong emphasis on the immutability of the model and strict flow on the interactions between the components of MVC. Model, View and Controller also get respectively renamed to Store, View and Dispatcher. An action submitted to the Dispatcher will update the Store with a new Store in a determinstic way, which will imply a redraw of the View.
Juan succeeded to mimic redux in the C++ world using his library immer. To demonstrate the capabilities of his library, Juan recreated an emacs-like editor. The beauty of having an immutable Store is truly expressed in the time-traveling machine that you can create from it: by saving all the states of the Store, you can easily come back to a previous state of your application (similar to undo / redo). You should absolutely watch the video to understand how easy it seems to implement this. On top of that you will have the chance to watch what might be the most audacious ending of a C++ talk I have ever seen.
[Talk] Reactive Equations - André Bergner - 💀💀💀 ★★★
As a meta-programmer aficionado, this was the most "devilish" talk, and therefore highly thrilling, I attended during the event. It was not the first time I heard from André Bergner, he attended the cppcon in 2015 and I remembered that he presented a nice way to have currying on your function. This time, André focused on reactive equations. If this sounds foreign to you, you might be more familiar with data binding in Qt QML using Javascript expression. André's reactive equations are similar but with simpler expressions:
// ***** Using a pseudo-language, let's define the equations *****
x : float
y : float
z : float
y = x * 42 // When x is updated, y will be automatically updated.
z = y + x // When y or x is updated, z will be automatically updated.
You may notice that I didn't write any C++ code. By default C++ would not permit to have expressions that update themselves by "magic" if one variable changes. You could write the update logic manually, but with a lot of long equations, this becomes very error prone. Instead André created a DSL (Domain Specific Language), which is equivalent to create a language within C++ itself. To define his DSL, André used expression templates. Expression templates are tricky creatures, which roughly consist in encapsulating C++ expressions into a type at compile-time. This type will retain all the operators / functions (let's call them operations) that you applied in your expression. These operations can be queried at compile-time to generate other expression that you will execute at runtime. In André's case, the encapsulated operations from his reactive equations would be used to automagically generate the update logic. To facilitate his task, André heavily relied on Boost.Proto. If you are versed in the art of meta-programming, this will certainely be entertaining to you!
[Talk] Free your functions - Klaus Iglberger - 💀 ★★★
This was a glorious hymn to our beloved free functions by Klaus Iglberger. Programmers often resort to use member functions and inheritance to provide polyphormism in C++, often overlooking that free functions and overloading would be a smarter choice.
Let's take a situation where you would need to implement a serialise function for a bunch of unrelated types. Would rather use the implementation 1?
struct serialisable {
virtual ~serialisable();
virtual std::string serialise();
};
struct A : serialisable {
std::string serialise() override { /* return something... */ };
};
struct B : serialisable {
std::string serialise() override { /* return something... */ };
};
Or the solution 2?
struct A {};
struct B {};
std::string serialise(const A& a) { /* return something... */ }
std::string serialise(const B& b) { /* return something... */ }
As Kate explained, it is complicated! If you are looking for runtime polyphormism, then you will certainely use the solution 1. If not, the solution 2 is actually preferable. It has a lot of advantages that Klaus explained for one full hour. My favorite one being that you can extend your polyphormism to types that you do not own. Let's say that you want to serialise std::vector, you can simply write an overload for it:
template <class T>
std::string serialise(const std::vector<T>& v) { /* return something... */ }
In practice, nothing prevent you from mixing a both solutions to your needs. One counter-argument being that free functions have an ugly syntax: v.serialise(); feels more natural than serialize(v);. That issue could have been solve with the unified call syntax proposal by Bjarne Stroustrup and Herb Sutter. Sadly, it was rejected by the C++ committee.
[Talk] Reader-Write Lock versus Mutex - Understanding a Lost Bet - Jeffrey Mendelsohn - 💀💀💀 ★★
- Slides: coming-soon
- Video: link
Jeffrey Mendelson from Bloomberg had a bet with a colleague on whether a readers-writer lock would be faster than a mutex to protect the access on a resource that could be written by a single writer, but could have multiple readers simultaneously. The readers-writer lock would follow exactly that behaviour (multiple readers, single writer). The mutex would keep the exclusivity to one writer or one reader only! Jeffrey lost the bet, but that did not hindered him from exploring the reasons behind his lost. It was challenging for me to grasp all the implications on this topic, but here is what I understood:
- Jeffrey's reader-writer lock was made of atomic variables to keep track of the amount of readers and writers. If the resource was currently written onto, the readers and other writers would wait onto a semaphor to be waken-up later on.
- If the amount of time spent by the readers or the writers on the resource is fairly long, the readers-writer lock will actually perform better than the mutex as multiple reader can process simultanesouly.
- On the other hand, if the writing and reading operations are very fast, the atomic operations on the counters will start to be costly comparatively. Atomics tend to have nonnegligible effects on the cache lines of your CPU(s). In this case, loosing the ability to have multiple readers is actually not as dramatic as you would think in comparison of stressing your cache.
- Jeffrey came up with an hybrid solution that combines both a readers-writer lock and a fallback to a mutex that outperformed the previous solutions.
Once the video of this talk is uploaded, I must have a complete rewatch of it. It always amusing that our intuitions can be entirely wrong when it comes to concurrency and programming.
[Other] The not-so-secret lightning talks
Videos: link, link, link, link, link, link
Before the last Keynote, we had the pleasure to listen to some not-so-unexpected lightning talks. I will not spoil too much of it!
I just want to express my gratitude to Guy Davidson and Sean Parent for bringing diversity in the C++ community under the spotlight. It was more than welcome and I am glad of these initiatives.
Conclusion:
Once again, I was amazed by the C++ community and how a group of dedicated persons can build such nice event. I am already eager to fly to one of the big conference next year: Meeting C++ or cppcon. I would also encourage anyone with a bit of passion for this language or programming in general to give a try to conferences or local groups, you will discover more than you would expect!