Making a STL-compatible hash map from scratch - Part 2 - Growth Policies & The Schrodinger std::pair
Posted on Mon 13 April 2020 in C++
This post is part of a series of posts:
- Part 1 - Beating std::unordered_map
- Part 2 - Growth Policies & The Schrodinger std::pair (Current)
- Part 3 - The wonderful world of iterators and allocators
- Part 4 - An insertion maze (Coming Soon)
In the previous post, we started a quest that consists in implementing an associative container similar to std::unordered_map in the C++ standard library. We saw two approaches that could help us in beating the performance of most std::unordered_map implementations: freeing ourselves from stable-addressing and swapping the modulo operation with some bit-wise operations.
Due to its layout, we called this new associative container a dense_hash_map. You can find a reference implementation right here.
Let's carry-on and start our own implementation right now!
Part 2 - Structuring our code & Dealing with value_type:
Preparing for the adventure:
Disclaimer: this section starts very gently, if your C++ e-beard or e-hair is already pretty long, you may want to skip to the Structuring our code section.
Like any hero starting her/his journey, we need to ensure we have the right items in our inventory.
For C++, here is my list of handy things to have when working on some standard-ish looking code:
- eel.is C++ draft, the holly bible of C++ itself (the latest draft of the C++ standard). eel.is's transformation of the standard latex source files to a clean HTML version is a godsent gift. You can navigate in each of the sections of the standard with ease. In our case, we will mainly refer ourselves to the sections unord.map, associative.reqmts and container.
- cppreference, the tuned-down version of the standard. This wiki is of great help when the lawyer language of the standard is too advanced for your taste (sometimes the standard feels downright insulting to your intellectual abilities). On some rare occasions, I have seen cppreference have slightly inacurate descriptions of the standard. It always nice to cross-check the holly bible and this wiki. In our case, we will most refer to the unordered_map section.
- godbolt to experiment quickly your ideas on different compilers and check how the standard reacts for certain use-cases. With the recently added feature that permits you to run code, godbolt is extremely handy. Goldbot's grand cousin, cppinsights can help you to explore complicated expressions.
- The C++ core guidelines, a bunch of C++ precepts written or more or less by those behind the holly C++ standard. When given multiples way of doing one task, the core guidelines will direct you towards the better way to achieve that task.
- Some linter and formatting tools. I personally like clang-tidy and clang-format.
- A good unit-test framework like catch2. Writing such standard-like code without writing unit-tests is like running naked towards a level 100 creature and expecting to beat it with a simple bamboo stick. Good luck to you to achieve that!
- A bunch of warnings applied to your compiler. For the unix-like compilers (GCC or clang), a bare minimum would be
-Wall -Wextra -pedantic -Werror.

And some optional items:
- A recent compiler that supports a recent version of the language (C++17 in my case). Technically, nothing prevents you to write standard-library-like code with ancient C++, but each version of the standard made it a lot simpler. This is especially true for the meta-programming part.
- cmake. Whether you find cmake's syntax an abomination or poetry, it is currently the de-facto standard build tool for any C++ projects. Just for that sake of consistency in the C++ ecosystem, I would advise to support some sort of cmake bindings for your project.
Structuring our code:
A header only Library:
Given that most of the classes, functions or even variables will have template parameters, there will be very little code that could end-up in its own compilation unit. So the dense_hash_map will be header library. The file layout is fairly standard:
├── CMakeLists.txt # Main CMakeLists.txt file that defines.
├── include
│ └── jg
│ ├── dense_hash_map.hpp # Main file to be included by users.
│ └── details # Folder that contains internal structures that users should not depend-on.
│ ├── bucket_iterator.hpp
│ ├── dense_hash_map_iterator.hpp
│ ├── node.hpp
│ ├── power_of_two_growth_policy.hpp
│ └── type_traits.hpp
├── tests # Unit-tests folder.
│ ├── CMakeLists.txt
│ └── src
│ └── dense_hash_map_tests.cpp
Note: as any C++ egomaniac would do when facing the hard issue of choosing a namespace for his/her project, I went for my initial "jg".
Our main class in dense_hash_map.hpp:
To be able to organise our code correctly, let's have look at the "dense" layout we saw in the last post:
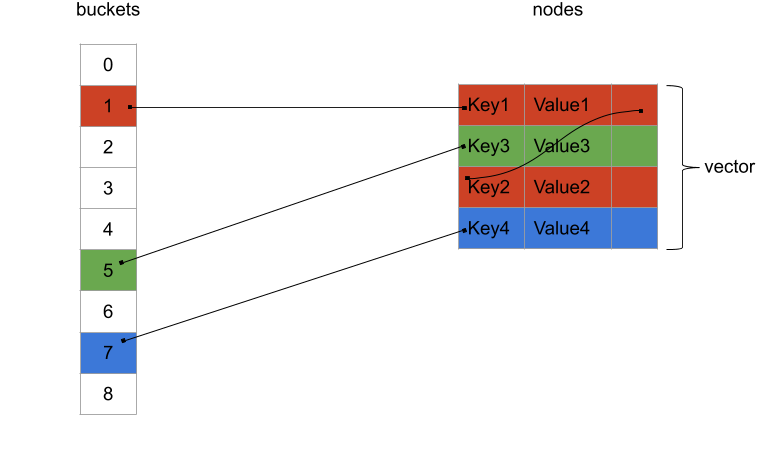
We will have two vectors:
- One for the buckets. More precisely, these are the indices for the first node of the linked-list of each of our buckets.
- One for all the nodes. These are the nodes in the interleaved linked-lists that hold the key/value pairs.
While we are crafting our dense_hash_map from scratch, it doesn't mean that we cannot reuse some of the other containers in the standard library.
Naturally, our two vectors will be some good old std::vector. Both of those will be members of our dense_hash_map class. If we inspire ourselves from std::unordered_map's signature, this gives us our first piece of code:
template <
class Key,
class T,
class Hash = std::hash<Key>,
class Pred = std::equal_to<Key>,
class Allocator = std::allocator<std::pair<const Key, T>>,
class GrowthPolicy = details::power_of_two_growth_policy
>
class dense_hash_map : private GrowthPolicy
{
private:
// Define some aliases to avoid further typing later on.
using node_type = details::node<Key, T>; // A node type that contains our key/value.
using nodes_container_type = std::vector<node_type>;
using nodes_size_type = typename nodes_container_type::size_type;
using buckets_container_type = std::vector<nodes_size_type>;
public:
// ...
private:
nodes_container_type nodes_;
buckets_container_type buckets_;
};
The buckets_container_type is dependent on the size_type of the nodes_container_type. In a std::vector, size_type is the type used for accessing elements using the subscript operator operator[]. It makes sense, since buckets_ contains indices for nodes_. Traditionnaly, and to the dismay of plenty, size_type is std::size_t which is an unsigned integer. We will use the value of std::numeric_limits<nodes_size_type>::max() to represent an invalid index into nodes_ or the end of our linked-lists:
static inline constexpr nodes_size_type node_end_index = std::numeric_limits<nodes_size_type>::max();
For instance, buckets_ will be initialized, at the construction of an empty dense_hash_map, with node_end_index since all the buckets are empty.
If you were attentive, you would notice that there was also an extra template parameter GrowthPolicy to dense_hash_map. Let's have a closer look at it!
Growth Policy:
In the last post, we discovered some bit-wise operation tricks to increase the speed when mapping a key to its bucket.
We also saw that there were drawbacks in doing so. So instead of forcing this design choice on our dense_hash_map users, we can make this behaviour a policy. The default policy will be the power_of_two_growth_policy:
// power_of_two_growth_policy.hpp
namespace jg::details
{
struct power_of_two_growth_policy
{
// Given a hash and the current capacity, use bit-wise trick to return the bucket index.
static constexpr auto compute_index(std::size_t hash, std::size_t capacity) -> std::size_t
{
return hash & (capacity - 1); // We saw that trick in the previous post.
}
// Given a desired new capacity for the bucket container, pick the closest power of two.
static constexpr auto compute_closest_capacity(std::size_t min_capacity) -> std::size_t
{
// We didn't see that trick yet.
constexpr auto highest_capacity = (std::size_t{1} << (std::numeric_limits<std::size_t>::digits - 1));
if (min_capacity > highest_capacity) {
assert(false && "Maximum capacity for the dense_hash_map reached.");
return highest_capacity;
}
--min_capacity;
for (auto i = 1; i < std::numeric_limits<std::size_t>::digits; i *= 2) {
min_capacity |= min_capacity >> i;
}
return ++min_capacity;
}
// Returns the minimum capacity (~= initial capacity) the bucket container must have.
static constexpr auto minimum_capacity() -> std::size_t { return 8u; }
};
}
All the growth policies will have to respect an implicit C++ concept: it must have the three static member functions compute_index, compute_closest_capacity and minimum_capacity.
These specific compute_index and minimum_capacity functions are self-explanatory. But compute_closest_capacity is interesting: it tries to find the closest upper power of two given a random capacity.
A clever way that achieve that task is to fill your capacity number in its bit representation with 1 starting from the right until you reach the highest bit already toggled on with 1. Afterwards, you can just increment and tada... you get your upper power of two.
Here is an example with the number 18 to clarify a bit (no pun intended):
18 (decimal) == 0001 0010 (binary)
^ Highest bit already toggle on.
After filling starting from the right:
0001 1111 (binary)
And if we add one:
0010 0000 (binary) == 32 (decimal)
compute_closest_capacity is doing exactly that with the operator |= and some bit-shifting with the operator >>. It handles the case where we already have a power two by substracting one before processing the number. We also cap the minimum capacity to the highest power of two we can represent to avoid an overflow in the result.
Note: you can also achieve a similar effect with some built-ins in your conpiler. For instance, GCC provides __builtin_clz which can be of great help.
Afterwards, we rely on the growth policy in our dense_hash_map by "using" its functions:
class dense_hash_map : private GrowthPolicy
{
using GrowthPolicy::compute_closest_capacity; // "Import" the policy's functions in this scope.
using GrowthPolicy::compute_index;
using GrowthPolicy::minimum_capacity;
// ...
constexpr void rehash(size_type count)
{
// ...
count = compute_closest_capacity(count);
// ...
}
};
So what's left of the first code snippet that we didn't dive into? The node type: details::node<Key, T>. By now, you should have a vague feeling that there is something is fishy with this one, it has its own class in the detail namespace. But is that so complicated to make a node holding a key/value pair?
Dealing with a const value_type:
So here is the deal, std::unordered_map has a peculiar value_type (value_type is the type you obtain as a reference when querying most containers in the standard library when using iterators) which is std::pair<const Key, T>. Whenever you supply a template argument Key, all the key/value pairs you obtain from std::unordered_map will have their first member, which is the key, stored as const Key. And, this, ladies and gentlemen, is can of giant worms ready to devore your last bits of sanity. So... let's open it!

When you think a bit more about it, this design prevents you to put yourself in serious troubles. You cannot mutate the keys in your associative container once you have inserted them. Typically, without a const Key, you would be able to do such crazy moves:
jg::dense_hash_map<std::string, hero> my_map{{"spongebob", hero{}}, {"chuck norris", hero{}}};
auto it = my_map.find("chuck norris");
it->first = "Chuck Norris"; // We are mutating the key to properly capitalise the venerable chuck.
// my_map after that would be in sad state.
When mutating a key, your key will very likely have a new hash (unless you are the lucky winner of a collision...) which means that it probably belongs to a new bucket (unless both hashes belong to the same bucket...). Sadly, there is no way for your container to be aware that you mutated a std::pair<const Key, T> it gave you as reference, which implies that the container cannot handle properly the hash change. Its internal data-structure would be in a broken state rather quickly. By having a const Key, the standard shields itself from this issue: the key becomes immutable.
Now, let's assume that our details::node<Key, T> has a std::pair<const Key, T>:
template <class Key, class T>
struct node {
nodes_size_type next = node_end_index; // Next index of the node in the linked-list.
std::pair<const Key, T> pair; // Our glorious pair.
};
With our "dense" design, this becomes a performance issue. Our std::pair<const Key, T> will have its move-constructor and move-assignment operator disabled forever and ever, and so does the node type. All our nodes are stored in a packed vector nodes_, which sometimes reallocate itself and send all its content into a bigger buffer. Not being to able to move our objects accross memory is a huge bummer. We would have to copy them around. That's unacceptable! Even more irritating, std::unordered_map does not suffer from this as its design allocates each nodes separately.
Big problems require big solutions hacks. Here are our two choices:
- We make a
std::pairtype on steroids that communicates back and forth with the container when the key change. This also requires our new type to be interoperable withstd::pair. It might be possible to partially fake astd::pairwith some implicit conversions, but we will never make ourdense_hash_mapa drop-in replacement that way. - We circumvent the type system with some type punning and create a Schrodinger
std::pairthat has both aKeyand aconst Keyas its first member. In other words, we store internally astd::pair<Key, T>in our node but expose it as astd::pair<const Key, T>to the user.
Obviously, the Schrodinger std::pair sounds the most dangerous creature of the two. So... let's pick it!
The Schrodinger std::pair:
C++ offers at least two official ways to perform type-punning: reinterpret_cast and unions.
reinterpret_cast:
reinterpret_cast sounds quite attractive: "it is purely a compile-time directive which instructs the compiler to treat expression as if it had the type new_type". But if you read closely along the standard lines, it has a very restricted usage. It is often used when casting to const char* (const std::byte*) to manipulate your types as raw data. But even doing so is harder than you expect. A fun-fact is that the classic pattern in many C++ code-base of reinterpret_casting a memory buffer to a POD is actually not allowed:
struct A {
int x;
};
const char* network_buffer = get_buffer();
// The following code is not allowed as explained by, you would need std:bless from p0593r2.
const A* my_a = reinterpret_cast<const A*>(network_buffer);
Clearly, reinterpret_cast is not our friend here. cppreference even gently warn us:
The behavior is undefined unless one of the following is true:
- AliasedType and DynamicType are similar.
...
std::pair<int, int> and std::pair<const int, int> are not similar.
union:
We are left with C++'s unions to perform our type-punning. Let's write one:
template <class Key, class T>
union union_key_value_pair
{
using pair_t = std::pair<Key, T>;
using const_key_pair_t = std::pair<const Key, T>;
template <class... Args>
union_key_value_pair(Args&&... args) :
pair_(std::forward<Args>(args)...) // Construct the active member.
{}
// Special members need to be explicitely defined for unions.
union_key_value_pair(const union_key_value_pair& other) {}
union_key_value_pair(union_key_value_pair&& other) {}
auto operator=(const union_key_value_pair& other) -> union_key_value_pair&
{
pair_ = other.pair_;
return *this;
}
auto operator=(union_key_value_pair&& other) -> union_key_value_pair&
{
pair_ = std::move(other).pair_;
return *this;
}
~union_key_value_pair() { pair_.~pair_t(); }
// Accessors to the two members.
pair_t& pair() { return pair_; }
const pair_t& pair() const { return pair_; }
const_key_pair_t& const_key_pair() { return const_key_pair_; }
const const_key_pair_t& const_key_pair() const { return const_key_pair_; }
private:
pair_t pair_; // Our active member.
const_key_pair_t const_key_pair_;
};
Unions have this concept of an active member: the latest member you constructed. You can only have one active member at a time for a union.
In our case, the active member will always be pair_, a std::pair<Key, T>, since this is how we truly want to store the pair.
It is also why we defined all the special members (copy/move constructors/assignment operators) in terms of the pair_ member.
Now the interesting question is what can we do with the "inactive member" const_key_pair_? Can we expose it to the user directly?
The standard is suprisingly quite clear on that topic:
One special guarantee is made in order to simplify the use of unions: If a standard-layout union contains several standard-layout structs that share a common initial sequence ([class.mem]), and if a non-static data member of an object of this standard-layout union type is active and is one of the standard-layout structs, it is permitted to inspect the common initial sequence of any of the standard-layout struct members; see [class.mem].
In rough terms, we will be able to access the inactive member const_key_pair_ if both std::pair<Key, T> and std::pair<const Key, T> share the same layout for their members first and second and both are standard-layout structs. If you take a look at all the three main standard libraries (libc++, libstdc++, MSVC's STL), we can assume that the first and second members will always be at the same position (no weird template specialisation going on). But having the guarantee that our pair types will be standard-layout structs is much harder. For that to happen, the types Key and T they store need to be standard-layout structs themselves.
Here we have to make a hard choice, to follow or not to follow the standard. Please, roll a binary dice and observe the result:
1 - To follow the standard:
We decided to listen to the standard and will stick to the standard-layout structs rule. In this scenario, we will conditionally enable our union_key_value_pair optimisation:
// Our safe fallback to store key/value pairs.
template <class Key, class T>
struct safe_key_value_pair
{
using const_key_pair_t = std::pair<const Key, T>;
template <class... Args>
safe_key_value_pair(Args&&... args) : const_key_pair_(std::forward<Args>(args)...) {}
// Accessors to the two members.
const_key_pair_t& pair() { return const_key_pair_; }
const const_key_pair_t& pair() const { return const_key_pair_; }
const_key_pair_t& const_key_pair() { return const_key_pair_; }
const const_key_pair_t& const_key_pair() const { return const_key_pair_; }
private:
const_key_pair_t const_key_pair_;
};
// Given a two types Key and T, checks if a pair of the two would be of standard-layout.
template <class Key, class T>
inline constexpr bool are_pairs_standard_layout_v =
std::is_standard_layout_v<std::pair<const Key, T>> &&
std::is_standard_layout_v<std::pair<Key, T>>;
// Given a two types Key and T, returns you the best storage for your pair: the optimised one or the safe one.
template <class Key, class T>
using key_value_pair_t = std::conditional_t<
are_pairs_standard_layout_v<Key, T>,
union_key_value_pair<Key, T>,
safe_key_value_pair<Key, T>
>;
We start by defining a safe container safe_key_value_pair. This container is not a union and has only one member of type std::pair<const Key, T>.
The accessors to the "two members" are behind the scene redirecting to only one member. This type will always perform a copy when moved accross memory, but hey... at least it is safe. Now, when you are crafting your node type, you can use the meta-function key_value_pair_t that checks whether your pair is of standard-layout and if we should optimise or not the storage. If the pair's type has a standard-layout, we can use the optimised union union_key_value_pair, if not, we fallback to safe_key_value_pair.
Finally, if we are so zealous about the standard, we can always add an extra safety net to union_key_value_pair:
template <class Key, class T>
union union_key_value_pair
{
static_assert(
offsetof(pair_t, first) == offsetof(const_key_pair_t, first) &&
offsetof(pair_t, second) == offsetof(const_key_pair_t, second)
);
// ...
}
This static_assert ensure that the first and second members are truly located in the same memory area in both std::pair<Key, T> and std::pair<const Key, T>. Even if one of the three main standard library implementation were to sabotage our union_key_value_pair by shuffling members, we would be warned about it!
0 - To dodge the standard:
Note: If you are a C++ purist that never abuse the standard or write his own undefined behaviour, here is the exact point in this post where you should use your jetpack and fly away to a better place.
In this scenario, we are as paranoid as Miro Knejp: clearly, the standard committee is trying to hide the true power of unions to us. Yes, we can pun!
Type-punning through unions have been unofficially supported in all three major compilers for longer than I am alive. Our case is quite safe, given that:
- Our types would differ from a single
const, this shouldn't have any impact on the size offirstnor its alignment. - We made the
constversion the inactive member that we expose to the user. Going fromTtoconst Tis a LOT safer than the other way around.
So, we will unconditionally use the union_key_value_pair container, but we will keep the static_assert from the previous solution.
We still want to ensure that the memory layout of std::pair<Key, T> and std::pair<const Key, T> are strictly the same.
By doing so, we will actually disrespect the standard once again: "the offsetof macro with a type other than a standard-layout class is conditionally-supported". Thankfully, the three main compilers do seem to support it! We can silence GCC's warning on that topic with a well-placed #pragma GCC diagnostic ignored "-Winvalid-offsetof".
Now, we have a fast container for our key/value pairs no matter the types we receive for Key and T.
Our last move will be a gesture towards our strict friends, we will wrap all our dangerously-undefined-type-punning into an #ifdef directive:
#ifdef JG_STRICT_TYPE_PUNNING
// Use the previous solution.
// ...
#else
// Use our hacky but fast solution.
template <class Key, class T>
using key_value_pair_t = union_key_value_pair<Key, T>;
#endif
/!\ On a more serious note: you should really be aware of the undefined behaviour of this solution. If your application is used in critical operations, you should refrain yourself from defying the standard. On the other hand, if your application is non-critical (or have a rock-solid release process), you could give a try on the fast type punning. Choose wisely!
Conclusion:
We survived this first day of our journey! We can control the growth of our container using a policy pattern. We also have a Schrodinger std::pair at our disposal to move our key/value pairs blazingly fast accross memory while preventing our users to shoot themselves in the feet.
Be ready for the next phase: the dreaded iterators and allocators are waiting for you!