Making a STL-compatible hash map from scratch - Part 3 - The wonderful world of iterators and allocators
Posted on Fri 01 May 2020 in C++
This post is part of a series of posts:
- Part 1 - Beating std::unordered_map
- Part 2 - Growth Policies & The Schrodinger std::pair
- Part 3 - The wonderful world of iterators and allocators (Current)
- Part 4 - ... (Coming Soon)
In the previous post, we prepared our data-structure to be able to store our key/value pairs in a performant way: our design permits us to expose, for safety, immutable keys to our users while internally having mutable access for speed. We also had fun with more bit magic to create a special growth policy for our bucket container. You can find a reference implementation right here.
At this point, you are probably eager to start working on the algorithms of our dense_hash_map. Alas, we are not there yet! Two new kind of challengers entered the arena: allocators and iterators. Like any word finishing by "or" (Terminator, Alligator, Abductor, Debtor, Elevator, Moderator, Emperor...) there is a certain violence or authority coming out of it of these twos. And rightfully so, having those in your project is a good indicator that you will spend nights banging your head against a brick wall.
Let me be your mentor and I will guide you through these tough areas!

Part 3 - The wonderful world of iterators and allocators:
Two iterators with two different endeavors:
If we base ourselves on the unordered_map's interface, we should have at least four different sorts of iterator:
| Name | Description |
|---|---|
| iterator | Iterate through all key/value pairs of the map |
| const_iterator | Similar to iterator but yields const references to the pairs |
| local_iterator | Iterator through all the key/value pairs in one bucket |
| const_local_iterator | Similar to local_iterator but yields const references to the pairs |
It becomes clear that we will actually need to create only two types of iterators: iterator and local_iterator. The other two can be easily derived from the first ones. We will just sprinkle some const where we should.
The interior of iterator:
If you wonder which kind of iterator to tackle first, iterator and its "little bro" const_iterator are probably the more interesting ones for our users.
Quite often you will want to iterate through all key/value pairs to perform some operations and this is what iterator is dedicated for.
More precisely, iterator is the type returned by begin, end & Co. which allows you to create a range-based for loop such as:
for (auto& [key, value] : my_map) {
std::cout << key << ", " << value << "\n";
}
The modern picasso in me decided to show you what this range-loop would do internally:
Yes, it should be as simple as iterating in our nodes_ container. No, it won't be as easy as you may think.
To iterate over the nodes_ container, we can simply use its own... iterators. Conveniently, nodes_'s iterator type is also following the concept
LegacyForwardIterator which is also needed for our dense_hash_map::iterator type.
Even better, it actually follows the LegacyRandomAccessIterator concept which is a powerful subset of the LegacyForwardIterator concept.
Sadly, nodes_'s iterator type has node<Key, T>& as its reference type when we need std::pair<const Key, T>& for dense_hash_map::iterator.
What we need is a projection onto the member pair of node<Key, T> while iterating over nodes_.
C++20 in all its splendor:
In an ideal world, we would have a C++20 compiler shipped with a fully C++20 compliant standard library. Within it, we would have the holly ranges library, which would permit to lazily transform our nodes_ into another one:
// ...
class dense_hash_map {
// ...
auto begin() {
return projected_range().begin();
}
auto end() {
return projected_range().end();
}
// ...
private:
auto projected_range() {
return nodes_ | std::views::transform([](auto& node){ return node.pair.pair(); });
}
// ...
};
The ranges library has its quirks and limitations as some fervent members of the lost C++ society will point out.
But for this kind of scenario, it is of great help. It is vastly superior to the C++17 solution as we will see.
You can easily implement cbegin and cend in a similar way: just make your projected_range function const.
std::views::transform even retains the concept of the ranges/iterators it is applied to, meaning that iterators it output in our case are still LegacyRandomAccessIterator.
In C++20, you can easily ensure that your iterator will be compliant using the newly adopted constraints and concepts features. Somewhere in your library, you could forge a static_assert such as:
static_assert(std::random_access_iterator<dense_hash_map_iterator<...>);
Let's assume that std::random_access_iterator had a compound requirement that ensure your iterator has a prefix increment operator as follow:
template <class It>
concept random_access_iterator = requires(It it) {
// ...
{ ++it } -> std::same_as<It&>; // Ensure that we can apply `++` to it and that it would return a reference.
// ...
};
If, in a moment of inadvertence, you were to remove that operator, your compiler would gently remind you about it. Here is how GCC puts you in the right track:
note: constraints not satisfied
required by the constraints of 'template<class It> concept random_access_iterator' in requirements with 'dense_hash_map_iterator it'
note: the required expression '++ it' is invalid
{ ++it } -> std::same_as<It&>;
C++ concepts are not just for meta-programming. It is also an elegant way to test your code with the help of your compiler. One could also hope that IDEs will in the future provide a convenient way to generate stubs from a concept. Of course, concepts have their limits when it comes to asserting actual runtime behaviour. Unit-tests are still your best ally for that!
The inferior C++17 solution:
As the Lieutenant-Colonel Bear Grylls would say: "the rules of survival never change, whether you're in a desert or in an old C++ project.". We are left on our own without any ranges at our disposal. We must forge our own iterator type by hand quickly!
While iterators are quite simple to use, writing them can be tedious. One has to scrupulously respect the concept your iterator supports. So in our case, we must implement all the contrainsts a LegacyRandomAccessIterator has. Which in turn, means implementing all the constraints a LegacyBidirectionalIterator has. Which in turn, means implementing all the constraints a LegacyForwardIterator has. Which in turn, means implementing... okkkk...ay... you get it. It's a list of constraints that no sane person would remember under normal circumstances.
Another old-school solution to avoid introducing any mistake in your iterator class is to cross-check all the members and free functions related to your class against an iterator of the same concept from a venerable library out there. In our case, we are writing an adaptor to std::vector's iterator. A good candidate for cross-checks could be libc++'s std::vector iterator. To do so, you would write unit-tests for all the members function for that iterator then try to apply them onto your own iterator.
/!\ Important note - I would strongly advise NOT TO COPY-PASTE from a library for various reasons:
- You could easily fall into plagiarism and all the legal issues around it.
- Your library probably does not have all the constraints a standard library has (naming, compatibilities...).
- You will not learn much out of it.
Given that C++20 is not fully mature in all major compilers, I went for the tedious C++17 solution. Thus was born dense_hash_map_iterator.
My iterator class takes five templates parameters:
template <class Key, class T, class Container, bool isConst, bool projectToConstKey>
class dense_hash_map_iterator {
// ...
};
The three first template parameters are rather obvious, it handles which Key / T pairs we will deal with and which Container type stores them.
The last two template parameters are here to kill multiple birds with one stone. Our iterator class will both represent iterator and const_iterator by setting the first parameter isConst. It also gives you the choice on which version of the Schrodinger std::pair we want to project onto with the projectToConstKey parameter.
Afterwards, we can start to define some important usings we can re-use within our class:
class dense_hash_map_iterator {
// ...
using projected_type = std::pair<
std::conditional_t< // Which version of the Schrodinger pair we want.
projectToConstKey,
const Key, // We want the one with an immutable key.
Key // We want the one with an mutable key that can be move around.
>,
T
>;
using sub_iterator_type = std::conditional_t< // Choose the underlying iterator type we want to work on: const or non-const.
isConst,
typename Container::const_iterator,
typename Container::iterator
>;
using value_type = std::conditional_t< // The value type our iterator will return depends on:
isConst, // <== The constness of our iterator `isConst`.
const projected_type, // <== The version of the Schrodinger pair we choose `projected_type`.
projected_type
>;
using reference = value_type&;
using pointer = value_type*;
// ...
};
Our usings form, in some way, a matrix of all iterator types we can get from the class template dense_hash_map_iterator. As the output of the matrix is the value_type type we will return and sub-iterator type sub_iterator_type we will work on. Writing the rest of the dense_hash_map_iterator becomes a rather boring task where almost every single call gets forwarded to a sub_iterator_ member. Here is a very mundane implementation of the prefix increment operator:
class dense_hash_map_iterator {
// ...
dense_hash_map_iterator() noexcept // Our main constructor that takes the sub-iterator we will project from.
: sub_iterator_(sub_iterator_type{}) {}
auto operator++() noexcept -> dense_hash_map_iterator&
{
++sub_iterator_; // Increment our sub-i... zZZzz zzZZZzzzzz
return *this;
}
private:
sub_iterator_type sub_iterator_; // Our sub iterator member.
};
I can predict that you are already virtually yawning at the idea of implementing the rest of this class. So instead of doing a long and monotonous listing of all these member functions, here are the "highlights" you should look for.
Given that value_type, reference and pointer depend on projectToConstKey, all the members functions (operator*, operator[], operator->) returning one of these types need to adapt their body to projectToConstKey. Our beloved if constexpr is back at it:
auto operator*() const noexcept -> reference // As soon as we observe the Schrodinger pair...
{
if constexpr (projectToConstKey) { // ... its state quantum state gets resolved.
return sub_iterator_->pair.const_key_pair();
} else {
return sub_iterator_->pair.pair();
}
}
This will correctly dispatch to the correct version of the Schrodinger std::pair at compile time. I am really glad that we do not rely on SFINAE for these constructions.
It is very handy to be able to assign an iterator to a const_iterator but not the other way around. The magic recipe behind such mechanisms consists in writing a rather awkward constructor:
template <bool DepIsConst = isConst, std::enable_if_t<DepIsConst, int> = 0>
// ^^^ Only if isConst is true....
dense_hash_map_iterator(const dense_hash_map_iterator<Key, T, Container, false, projectToConstKey>& other) noexcept
: sub_iterator_(other.sub_iterator_) // ^^ ... we have a constructor that take non-const iterator.
{}
Once again, the absence of C++20 can be felt here. We want this constructor to be available only when isConst is true: in other words only a const_iterator has this extra constructor. In C++20, a well-placed requires clause would conditionally enable that constructor. But in C++17 we have to resort to an disgusting SFINAE trick using std::enable_if_t. To make the matter uglier, the complicated rules of template substitution forces us to have the somewhat useless default argument DepIsConst instead of using isConst directly.
If you want to benefit from your conversion constructor within all your operators of arity 2 (operator==, operator<...), you must be careful on how to craft those. You have different options here: members, non-members, friends, non-friends, template or not template... I find Natasha Jarus explanations on the subject pretty good.
I opted for the option "give access to a const reference of my sub-iterator to everyone", including my operators defined as free functions. It avoids a creating a cluster-fudge of forward declarations and friends at the price of exposing my private parts. No fame, no shame as they say!
A quick note for some detractors:
Our beautiful C++20 solution expressed in few lines, became 207 lines of pure... iterator chaos. Certainly, ranges, concepts or coroutines can do more harm than good under some circumstances. Typically, the next iterator we will work on would not be a good fit for ranges. But entirely discarding their usage due to some limitations is not a smart move either. They do bring a lot of value as clearly shown with our dense_hash_map_iterator!
local iterator - a forward iterator without glamor:
local iterator is the crippled little cousin of iterator. To start with, its name badly represents what it does: what sort of locality is this about?
It cannot be easily expressed using range views due to its access pattern. And to finish, it is a mere LegacyForwardIterator and can hardly be more than that.
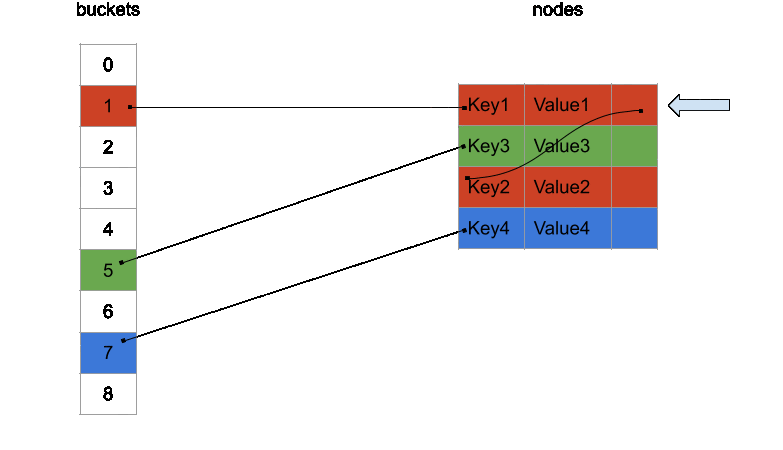
What this ill-named iterator gives you is an access to a specific bucket, i.e jumping through all the pairs that have keys whose hash collide. Here is what an iteration in a bucket of size two would look like:
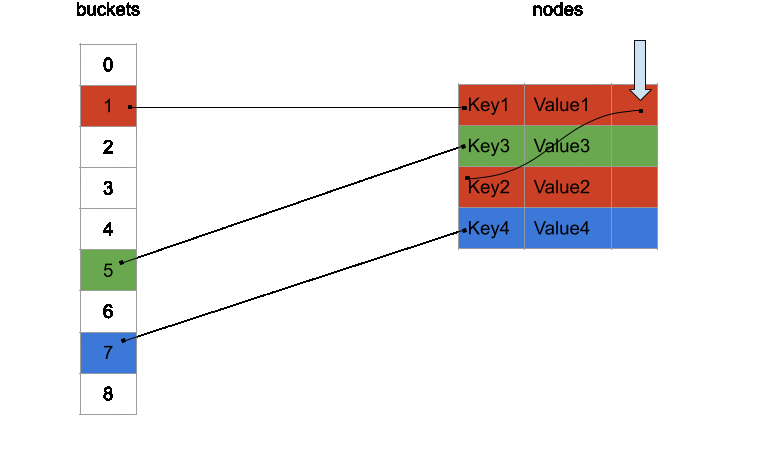
Here Key1 and Key2 hashes collide, so our iterator started on bucket 1 yields both of these pairs.
To reflect the true purpose of this iterator, I named it bucket_iterator.
Internally, our bucket_iterator can be used in conjunction with some of the standard algorithms.
For instance, we can apply a std::find_if to quickly pin-point a pair with a given key if we already know this key belongs to a specific bucket. Externally, I am not quite sure who uses this local/bucket iterator. My wild guess is that sometimes you want, as a user, to fine-tune your hashes or the load_factor of your hash map. This local iterator gives you the ability to debug your hash-map without too much hassle.
Whether this was worth a standardisation or not, I am not exactly sure. You shouldn't go against the sacred standard, so a local iterator in your hash map you should have.
The class bucket_iterator ends-up being very similar to dense_hash_map_iterator. In fact, it takes exactly the same template parameters for the same purpose. It is also a lot smaller since it is only a LegacyForwardIterator. It mainly differs in its increment operator and dereference operator since we are jumping around rather than doing a linear scan:
class bucket_iterator {
// ...
auto operator++() noexcept -> bucket_iterator&
{
current_node_index_ = (*nodes_container)[current_node_index_].next;
// ^^ ++ == moving to the next node in the linked-list.
return *this;
}
auto operator*() const noexcept -> reference
{
if constexpr (projectToConstKey) { // Still using the if constexpr trick to get the right Schrodinger pair.
return (*nodes_container)[current_node_index_].pair.const_key_pair();
// ^^^ Dereferencing means looking at the node at the current index.
} else {
return (*nodes_container)[current_node_index_].pair.pair();
}
}
private:
nodes_container_type* nodes_container; // The container of all nodes.
node_index_type current_node_index_ = node_end_index<Key, T>;
// ^^ The index of the current node we are on. ^^ By default we are pointing to "nowhere", the end node.
};
As you can see, this is nothing more than a classic iteration over a list. But instead of using a "next pointer", we have a next index. We cannot produce a bidirectional iterator as we would need a previous index, neither we can have random access due to the dereference step.
The last part of the puzzle for our iterators is a conversion function. After doing a std::find_if on a bucket_iterator it can be really convenient to send as a result a more useful iterator to our users. In a simplified form of this function looks like this:
template <class Key, class T, class Container, bool isConst, bool projectToConstKey>
uto bucket_iterator_to_iterator(
const bucket_iterator<Key, T, Container, isConst, projectToConstKey>& bucket_it,
node_container_type& nodes
) -> dense_hash_map_iterator<Key, T, Container, isConst, projectToConstKey>
{
if (bucket_it.current_node_index() == node_end_index<Key, T>) {
return {nodes.end()};
} else {
return {std::next(nodes.begin(), bucket_it.current_node_index())};
}
}
There are two cases:
- If our
bucket_iteratoris at the end of the linked-list, it means that it points to nowhere. Therefore, we return adense_hash_map_iteratoralso pointing at the end. - Otherwise, we grab the current index our
bucket_iterator. We then extract the begin iterator of our container of nodes and moving until that index. We can then craft adense_hash_map_iteratorout of it. Since our container's iterator is random access this conversion has very little cost.
Enough with iterators and let's move onto allocators!
A special constructor for allocators:
In the C++ lore, we have other "or" contenders when it comes to annoyance: allocators. At this point I am assuming that you all know what an allocator does: it allocates memory for the objects stored inside a container. But C++ being C++, it becomes a bit more tricky when you have containers of containers.

Nested containers and their allocator:
Let's try to play around with a container that would be very similar to our dense_hash_map::nodes_ (a vector of pairs), and see how it reacts to custom allocators:
struct debug_pmr_resource : std::pmr::memory_resource // pmr memory resource == allocator on steroids.
{
auto do_allocate(std::size_t bytes, std::size_t alignment) -> void* override
{
std::cout << "Allocated: " << bytes << "\n"; // We will print a message everytime something has been allocated.
return std::pmr::get_default_resource()->allocate(bytes, alignment); // Forward to the default allocator of your app.
}
void do_deallocate(void* p, std::size_t bytes, std::size_t alignment) override
{
std::pmr::get_default_resource()->deallocate(p, bytes, alignment); // Forward to the default allocator of your app.
}
auto do_is_equal(const std::pmr::memory_resource&) const noexcept -> bool override
{
return true; // Our resource has no state, all instances are the same.
}
};
debug_pmr_resource my_resource;
std::pmr::vector<std::pair<std::string, std::string>> nodes{&my_resource}; // We feed our pmr resource to a pmr vector.
auto some_long_string = "WinnieLoursonEstChauveCommeUneSouris"; // String long enough to disable small string optimization.
test.emplace_back(some_long_string, some_long_string); // Should construct a pair of two strings.
// Prints on godbolt:
// Allocated: 64
Before we dive a bit more into this code snippet, all standard containers with a prefix pmr are just the same usual containers with a predefined polymorphic allocator. This new allocator saves you from the hassle of writing an allocator the old fashion way. All you need to do is to write a resource with three member functions as shown here. Polymorphic allocators are worth a longer post that I will never write. In the meantime, I suggest you to use your google-fu to find some nice articles or videos about it.
Back to our snippet... Right here we have an external container std::pmr::vector which takes our resource/allocator and then we construct two strings (some internal containers) in it. How many allocations are we going to see from debug_pmr_resource's point of view? The answer is one and only one. The vector's buffer will be allocated through debug_pmr_resource but not the buffers of our strings. It is unfortunate to be in such a situation. As a user of some custom allocators, you really want all related objects to be stored in the same pool of memory, even more when this objects are nested structures.
Does this means that you need to make both of these strings "pmr" too and feed them with the debug_pmr_resource at construction? Well, yes and no.
Changing std::string to std::pmr::string is necessary. std::allocator (std::string) and std::polymorphic_allocator (std::pmr::string) are not the same type, there is no C++ world where both of those could be compatible. But the feeding of my_resource is not necessary. There is a mechanism already in place from the standard that mandates that our external container nodes would forward its allocator to its inner containers (the two strings) if the allocator type they use is the same. We can easily check that:
debug_pmr_resource my_resource;
std::pmr::vector<std::pair<std::pmr::string, std::pmr::string>> nodes{&my_resource}; // Note our string are also prefixed by pmr now.
auto some_long_string = "UnPangolinVautMieuxQueRien";
test.emplace_back(some_long_string, some_long_string);
// Prints on godbolt:
// Allocated: 80
// Allocated: 27
// Allocated: 27
Hurray, we see two more allocations going through the resource! With a size of 27, it must really be some buffers storing UnPangolinVautMieuxQueRien plus \0. The allocator forwarding is happening!
The next step for us is to be sure that we can achieve the same success not only with std::pair<std::pmr::string, std::pmr::string> but also with our node type we defined in the previous post: the type that store both a Schrodinger std::pair and a next index.
debug_pmr_resource my_resource;
std::pmr::vector<node<std::pmr::string, std::pmr::string>> nodes{&my_resource}; // Using our node type.
auto some_long_string = "FreedomFriesAreTooGreasy";
test.emplace_back(0, some_long_string, some_long_string);
// ^ index
// Would print:
// Allocated: xx
Bjarne damn it! We have lost the allocator forwarding again! That's unnacceptable for our dense_hash_map internals.
Given that only difference is std::pair and node, should we start to investigate what makes std::pair so special?
To be a good investigator:
"If you stare into the C++ standard, the C++ standard stares back at you." - Nietzsche
If you have a look at the pages from the standard or cppreference about std::pair you will not find anything useful to us. There are no mentions of allocators in its constructors. How did that even work?
I am not a sadist, so I will help you a bit. The response to your answer is in std::uses_allocator in C++17. This type-trait is used when constructing objects within your allocators (more precisely in std::make_obj_using_allocator in C++20). It let you check if the object you are creating using your allocator takes an allocator itself! Here comes a shortened explanation.
There are two ways std::uses_allocator will detect your object can receive an allocator:
- If it has a member typedef
allocator_type. - If
std::uses_allocatoris specialised to return true for your object type.
Of course, std::pair respects NEITHER of those rules. But here is the caveat:
As a special case, std::pair is treated as a uses-allocator type even though std::uses_allocator is false for pairs (unlike e.g. std::tuple): see pair-specific overloads of std::polymoprhic_allocator::construct and std::scoped_allocator_adaptor::construct (until C++20)std::uses_allocator_construction_args (since C++20).
Somewhere, deep in a cave, there is a C++ standard committee troll frenetically enjoying his/her/its joke on us with std::uses_allocator returning false EVEN THOUGH std::pair will be correctly forwarding allocators. Please don't feed it, he/she/it has done enough damage here.
Harnessing std::uses_allocator's power:
Unlike the troll, we cannot change the standard to fit our node type. So we need to use std::uses_allocator the proper way.
We will start by adding a specialisation to signal that our type wants to forward allocators:
namespace std
{
template <class Key, class T, class Allocator>
struct uses_allocator<node<Key, T>, Allocator> : true_type
{
};
}
All these constructors must take a std::allocator_arg_t tag parameter to differentiate them from the others, the non-allocator-forwarding ones. The second parameter is always the instance of the allocator itself alloc and the rest are the parameters you would find in their non-allocator-forwarding equivalents. As I just implied, you must have exactly the same amount of allocator-forwarding constructors as you have normal ones! You must be able to do all operations with or without involving allocators.
As soon as we have an alloc we can send it deep down to the Schrodinger pair. The Schrodinger pair must then construct its mutable std::pair variant taking that allocator in consideration:
This expresses that for any node and any Allocator, an instance of node can receive an instance of allocator to forward it deep down.
By which mean the instance of node will receive that instance allocator? With some special constructors:
template <class Key, class T>
struct node
{
// ...
// ...
// Constructor that takes arguments to make an index and a pair.
template <class Allocator, class... Args>
node(std::allocator_arg_t, const Allocator& alloc, node_index_t<Key, T> next, Args&&... args)
: next(next), pair(std::allocator_arg, alloc, std::forward<Args>(args)...)
{}
// Copy constructor.
template <class Allocator, class Node>
node(std::allocator_arg_t, const Allocator& alloc, const Node& other)
: next(other.next), pair(std::allocator_arg, alloc, other.pair.pair())
{}
// Move constructor.
template <class Allocator, class Node>
node(std::allocator_arg_t, const Allocator& alloc, Node&& other)
: next(std::move(other.next)), pair(std::allocator_arg, alloc, std::move(other.pair.pair()))
{}
private:
nodes_size_type next = node_end_index; // Next index of the node in the linked-list.
key_value_pair_t<Key, T> pair; // Our glorious Schrodinger pair.
};
All these constructors must take a std::allocator_arg_t tag parameter to differentiate them from the others, the non-allocator-forwarding ones.
The second parameter is always the instance of the allocator itself alloc and the rest are the parameters you would find in their non-allocator-forwarding equivalents. As I just implied, you must have exactly the same amount of allocator-forwarding constructors as you have normal ones! You must be able to do all operations with or without involving allocators.
As soon as we have an alloc we can pass-it deep down to the Schrodinger pair. The Schrodinger pair must then construct its mutable std::pair variant taking that allocator in consideration:
template <class Key, class T>
union union_key_value_pair
{
//...
template <class Allocator, class... Args>
union_key_value_pair(std::allocator_arg_t, const Allocator& alloc, Args&&... args)
{
auto alloc_copy = alloc;
std::allocator_traits<Allocator>::construct(alloc_copy, &pair_, std::forward<Args>(args)...);
}
//...
};
Once again, union_key_value_pair uses the tag type std::allocator_arg_t to be sure not to collide with other constructors.
We will then construct the pair_ in place ; meaning that we will skip the memory allocation part of it since we already have the storage for it. Constructing an object in C++17 with an allocator requires you a PhD in C++ arcaneries: you need a non-const instance of that allocator coupled to the allocator_traits. C++20 can once again save you some time here with std::make_obj_using_allocator.
And on this positive note we are done with allocators! Our node class has the same behaviour a std::pair, it will reuse the allocator it was allocated with for its own members.
Conclusion from the author:
It was quite a labor to implement the iterators types for our dense_hash_map. We also discovered with stupor that allocators are not working out of the box for custom types. To have or not to have access to C++20 is also a huge factor in how easily you can write such code. C++17 demands a lot more rigor when dealing with "standard" code.
I have been selling these blog posts as us building a hash map together... so I am assuming that you are quite in furor by now since all the prior posts and this one did not contain a single line of algorithms. The rumor is that the next post will be about a maze of insertion algorithms, so stay tuned!